kaggle「Foursquare - Location Matching」に参加しました

kaggleの「Foursquare - Location Matching」にshunya iidaさんと参加しました。1083チーム中46位でした*1。
日本人kagglerが沢山参加していて盛り上がっている&NLPの経験を積みたい、ということでH&Mコンペが終わった後、5月中旬から参加しました。 ユニークな題材かつ、テキストの特徴量化や各種高速化・メモリ節約の工夫を学ぶことができて個人的にはとても良コンペでした*2。とくにユニークな手法を構築できたわけではなく、既出の各種アプローチを適用しただけですが、個人的な備忘録として解法や工夫をまとめたいと思います*3。
コンペ内容
位置情報のプラットフォーマである「Foursquare」のデータが題材です。データには、各レコードごと店舗や施設の名前・住所・座標・カテゴリ・URL・電話番号が含まれています。このレコードから各店舗・施設を識別するPOI(Point Of Interest)が同一な組み合わせをマッチングさせるのがコンペの目的です。同一のPOIであっても、各情報は、座標が少し違ったり、名前や住所の表記が異なっていたり、欠損があったりと、情報に揺らぎがありました。これらの揺らぎの中で各ペア間の類似性を評価し、マッチング判定をするコンペでした。
解法
ベースライン
中盤からの参加ということもあり、PENGUIN46さんの公開Notebook (Foursquare - LightGBM Baseline)をベースラインとして使用させていただきました。
<ベースラインのアプローチ>
- マッチング候補を抽出する1st stage、同一POIかどうかの2値分類モデルの2nd stageという構成
- マッチング候補の探索範囲をtestと合わせるため、学習データをPOIでGroupKFoldして2分割した上で1st stageに掛ける
- 基本的にマッチングするのは同一のcountryなので、1st stageの処理は国別に行う
- kNNで各レコードごと座標の近傍点を10ずつ抽出しマッチングの候補とする
- マッチしたレコード同士の各文字列の編集距離、kNN時点で算出した座標間距離を特徴量に同一POIかどうかの2値分類モデルをLightGBMで構築
- マッチしたペアの逆向きを補完するpost process(A-Bがマッチ判定されているがB-Aが漏れているときにB-Aを復元する)
アプローチの基本コンセプト、編集距離の並列化・cythonによる高速化など非常に参考になりました。基本的にはこのノートブックを改良していきました。
1st stageの改善
1st stageで抽出する近傍点を10から増やしていけばマッチペアの取りこぼしは無くなっていきますが、線形的にデータ数は増え、メモリ負荷・処理時間も増加していくことになります。コードコンペのためどちらも有限であり、一定以上に到達するとサブが回らなくなってしまいます。サブが回る範囲のデータ数の中で、如何に効率よくマッチングペアを拾えるかというのが重要でした。
単一の算出方法で近傍点の数を増やしていくと段々外ればかり引いていくことになり、効率が良くありません。そこで複数の算出方法を組み合わせる形を検討しました。具体的には、nameのtfidf類似度を加え、距離15 + name tfidf類似度15で1stのマッチング候補抽出を行いました。
2nd stageの改善
元々の特徴量に加えて下記のような特徴量を加えました。
- categoriesの一致率
- tfidfの類似度(name, categories)
- BERT(distilbert-base-multilingual-cased)事前学習モデルのembeddingの類似度(name, categories)

LGBMの特徴量重要度
tfidfの設定
1st, 2ndともにtfidfの類似度の寄与が非常に大きかったので、この部分を特出しで。
tfidfのfitはcountryごと行いました。また、最初は容量的なことを考えてSVDで圧縮をしていたのですが、実際はtfidfの結果はスパースマトリクスで保持されるため容量の負荷は大きくありませんでした。スコア的にも無圧縮の方が良かったのでこちらを採用。
またtfidfのパラメータも色々とiidaさんが検討してくれていて、最終的にはngram_range=(3,3)、analyzer="char_wb"の設定に。こちらもスコア向上に寄与しました。
CV
CVはPOIのgroupKFold2分割で行いました。推論用のモデル構築は、POIのgroupKFold2分割でそれぞれ1st算出・concatしたデータを作り、2ndを目的変数でのStratifiedKFold (n_fold=5)で行いました*4。
kaggle環境での推論に関する工夫
コードコンペなのでkaggle環境で推論を行う必要があり、RAMと実行時間に非常に厳しい制約がありました。この制約内で推論を行うために色々と試行錯誤しました。
%%pythonで1st / 2ndを分離
マジックコマンドの%%pythonを1st stageの処理部に記載することで、独立したプロセスとして実行されます。2nd実行時は1stの処理で変にメモリが掴まれていることもなく、クリーンな状態で実行でき、メモリ問題が良化しました。
2ndのバッチ処理化
test全体で推論処理を回すとメモリエラーが発生しました。推論処理はcountryで閉じた形なので、countryのgroupKFold (n_fold=5)でループを回しました。
ForestInference
推論はforestinferenceを使いました。LGBなどのモデルを使って簡単にGPUで推論できます。わりとpopularなようですが初めて使いました。とても便利。
BERT embベクトルをdictで保持
BERTのembeddingベクトルを類似度計算に使いますが、全てベクトルで展開してしまうとメモリ的にきつい。ということで、各文字列のユニークlistに対してベクトル算出し、その結果をdictで保持しました。ペア間の類似度を計算するときにはループを回して逐次的に取り出して使います。
類似度の計算方法
元々、sklearnのcosine_similarityを使ってましたが、numpyで普通に計算した方が早かったのでこちらに変更。
cumlでkNN
cumlのkNNを使うことで処理が高速化*5。
重複ペアの削除
A-Bのペアがあったときに、B-Aのレコードを削除しました。A-Bがマッチング判定されれば後処理によってB-Aが復元されるため結果には影響せず、大きくデータ量を減らすことができました*6。
試したけどうまくいかなかった
1stのtfidf name類似度近傍抽出に距離しきい値設定
nameは似てるけどすごく遠い候補を削除する。cvでは効いたがLBで悪影響あり、不採用
2nd特徴量に1st抽出時のrankを追加
cvでは効いたがLBで効かず...
nameのカウントエンコーディング
チェーン店とそうでないものでは類似度の価値も違うと思い、nameの希少度をカウントエンコーディングで表現。cvでは効いたが(略)
いろいろなembedding
- S-BERT
- universal sentence encoder
- BERTのファインチューニング(時間も経験も足りず)
参考にした記事
shopeeに関する記事をかなり参考にさせていただきました。
naotaka1128.hatenadiary.jp lab.mo-t.com Shopee - 2nd Place Solutionと上位解法まとめ - Speaker Deck
まとめ
楽しかったけどリークがあって残念だった(小並感)
2022年の目標(個人のOKR)
下記の通り、雑にtwitterで2022年の目標を掲げたのですが、
2022年目標
— T88 (@take213) 2021年12月30日
・kaggle金×2
・シミュレーションコンペ出る
・統計検定準1級
・atcoder触る
・業務で成果出す
・数学の苦手意識潰す
nishibaさんが言及されていた松岡玲音さんの投稿を読んで、しっかりと言語化しておく事は意味があるなと思い、改めて目標を設定しようと考えました。
いつか一緒に働きたいけど、なかなか同じ場所にならないですね。個人のOKRを立てるのは良いですね。ちゃんと仕事以外の項目も入っているのが良い。
— nishiba (@m_nishiba) 2022年1月1日
2021年が濃すぎて振り返りきれない|松岡玲音 @lain_m21 #note https://t.co/LQoYa0x7cl
上記投稿を模倣し、個人のOKRという形で2022年の目標を設定します。
※ちなみにOKRって何だっけ、と思い、下記の本を読みなおしました。

OKR = 目的(O) + 重要な結果指標(KR)
「目的」に向かうマイルストーンが「重要な結果指標」であり、どの程度達成できているかを指標で計測することで、ペースの見直しができるようになります。 また、「目的」の達成基準を明確にするためにも、「重要な結果指標」は計測可能な指標であることが求められます。
Objective1 : データサイエンティストとしての市場価値を高める
近々、転職も視野に入れている。その際に自分の希望通りの転職ができるように市場価値を高めておきたい。
KR1 : kaggleで金メダル×2
要件にkaggleを挙げる企業も増えており、成果としてもわかりやすい。 ただ日本でもExpert・Masterは順調に増えており、価値が目減りしていくことが想定される。 差別化要素として謡うことを考えると、2023年くらい迄にはGMになっておきたい。 残り4枚の金メダルを取る必要があるので、逆算して今年は金メダル×2を目指したい*1。
KR2 : 未経験のコンペ(シミュレーション、セグメンテーション、最適化)に参加する
対応できるタスクの幅を拡げておきたい。 現業ではその機会は限定的なので分析コンペを活用する。 まだ触ったことがない、シミュレーション・セグメンテーション・最適化のコンペを触ってみる。
KR3 : パブリックな場での情報発信を計5件以上行う
現状、会社の事業部内では色々と発信しているが、市場価値の向上という点では、パブリックな場での情報発信が重要となる。 blog・Qiita・note・zennなどテキストベースでの情報発信、LT会などの登壇、方法は問わず計5件以上の情報発信を目指す。
KR4 : 仕事において定量的な成果創出に至る事例、若しくは組織力強化に強く紐づく事例を2件以上作る
現業で何を達成したか、胸を張って語れるようになりたい。 一つは定量的な成果に繋がる事例。お客さんのビジネスに積極的に踏み込んでいき、ビジネス成果創出に拘る。 一つは組織力強化に紐づく事例。チームとしての未来を考え、専門性を向上・立地を確立するような事例を作りたい。
KR5 : 統計検定準1級、統計検定1級、AWS SAA / SAO / DOP、IPA STのうち、3つ以上取得する
スキル伸長のマイルストーンとして資格を取得する。 会社の資格報奨金対象資格から関連性の高い資格をピックアップした。 統計検定準1級、AWS SAAは必達目標として、その他の資格を1つ以上取得する。
Objective2 : 私生活で人生の幅を拡げる
ついつい、仕事や勉強に意識が向きがちなので、意識的に私生活で楽しい時間を作ることを目指す。 人生の幅を拡げるため、今までやったことがないことに挑戦したり、ついつい後回しになってしまっていることを意識的に行う。
KR1 : キャンプに2回以上いく
前々からキャンプに興味を持っていて、妻や子どもも行ってみたいと言っている。 まずはグランピングから始めて、最終的にはテントを張った本格的なキャンプを経験したい。
KR2 : 両手でピアノが弾けるようになる
娘が今年からピアノ教室に通っており、その関係で電子ピアノも購入した。 ギター・ベースは経験があるが、ピアノは右手で何とかメロディをなぞる程度。 ピアノを両手で弾けるようになりたい。
KR3 : 技術書以外の本を30冊以上読む
元々読書が好きだが最近は中々時間が取れていない。 冊数に拘る必要はないが、技術書以外の本を30冊以上読める程度の読書時間は捻出したい、という思い。
KR4 : ハーフマラソンに出場する
コロナで最近はマラソンも中止が多いが、今年は開催されることを期待したい。 健康に気を付けないといけない年齢なので、ハーフマラソン出場を道標に動ける体を取り戻したい。
さいごに : 一番意識したいこと
最近、「エフォートレス思考」という本を読みました。

色々と目標を立てましたが、達成のために無理をしないこと、楽しむことを意識して2022年を過ごしたいと思います。
*1:ただし、tierに拘り過ぎず楽しむことを第一としたい
2021年を振り返る
今年も一年の振り返りを。
(もはやそのためだけのブログです)
仕事
前年からチームで行っていたスキル強化活動を事業部全体に展開しました。
ナレッジ共有基盤での知見共有は大分活発になりました。アドカレもほぼ全枠埋まりました。
加えてLT会も立ち上げ、毎月回していくことができました。
参加者からの評判も上々で、組織内での学びあいを促進できているという手ごたえがあります。
来年以降はパブリックな場でも発信できるような形に進化させていきたいです。
実テーマの方は、修羅場だった去年と比べるとだいぶ落ち着いた一年でした。
その分、一つ一つの仕事の品質を上げられていたか、というと疑問符がつきます。反省。いくつか新しい領域のタスクに取り組めたのは良かったです。
ここ数年は異動当初のような自身の成長を感じられていません。
現職に留まるか、外に出るのか。
いずれにせよ、来年はもっとスタンス取りつつ、業務での成果創出・組織/自身の成長に拘りたいです。
kaggle
Riiidとcassavaで銀、outdoorで金を取って、Masterに昇格することができました。21年頭は銅×3のみの状態だったので、今年は大きく前進できたと思っています。
KCY2021グランプリ候補のcassavaは置いておいて、Riiidとoutdoorは結構リソース掛けてちゃんとそのリターンがあったので満足しています。
inclassで音系、振るわなかったですがchaiiでNLPに触れられたのも良い経験でした。
やはり最終的にはGMになりたいので、今後も金メダル獲得をひとつの目標にコンペに参加していきたいです。
あとはシミュレーションコンペにも興味があるので何かしら出てみたいですね。
勉強
何を学ぶにしても数学力のなさを痛感します。
このボトルネックを解消するため、高校数学まで戻って青チャートで学習を始めました。毎日数ページずつやってますが、すでにだいぶ楽しくなってきています。ある程度応用範囲がイメージできる今だからこそ勉強にも身が入る気がします。引き続き基礎固めを行い、数学の苦手意識を無くしていきたいです。
統計検定準1級取得を目的としていましたが、結局受けませんでした。来年の早いうちに取得してしまいたい。
クラウドの使いこなし、ということでAWSをちょくちょく触ったりしました。
今後業務でも触れる機会が多くなりそうなので、もっと仲良くなりたいです。
アルゴ×数学本を読んで、俄かに競プロに興味が湧いてきた今日この頃です。来年少し触ってみたい。
生活
子どもは順調に成長していて娘4歳、息子2歳になりました。
喜ばしいですが家がだいぶ狭くなりました。やはり戸建に引っ越したい。
とするとお金がいるよな、ということで最近お金のことばかり考えています。
来年は、本業の収入増、副収入の可能性についても検討していきたいです。
おわりに
主にkaggle関係でtwitterでやり取りできる方も増えて大変楽しい1年でした。
来年は積極的にチーム組んでいきたいです。どうぞよろしくお願いします。
kaggle「Google Smartphone Decimeter Challenge」に参加しました
8/5まで開催されていたkaggleの「Google Smartphone Decimeter Challenge」(通称outdoorコンペ)に参加していました。810チーム中7位ということで幸運にも金メダルを取ることができました。

解法はディスカッションに投稿しましたが、ここではもう少し詳細に、ポエム成分を追加しながら、コンペを振り返りたいと思います。
コンペ概要
GPSに代表される、人工衛星による位置測位システムGNSSに関するコンペでした。車両に設置されたAndroidスマホのデータを元におおよそ1秒ごとの車両の位置を推定します。

舞台はシリコンバレーで一回のドライブごとデータがまとまっていました。

一口にシリコンバレーといっても、高速道路は遮蔽物が少なく高精度に測位可能、ビルに囲まれた市街地は測位が難しいなど、エリアごと性質に違いが見られました。


与えられたデータは、大別すると下記のとおりです。
- ホストにて算出したベースライン
- ベースライン算出の元となったGNSS関連のデータ
- 加速度などのIMUセンサデータ
序盤はベースラインのデータに対して、異常値除去やスムージングなどの後処理を行うアプローチが検討されていきました。上位に食い込むためには、GNSS関連のデータへのアプローチが重要だったように思います。
解法
大きく分けると下記4つのアプローチをとりました。
- ベースライン改善
- 相対座標の推定
- 異常値除去
- 後処理
ベースライン改善
ホストが算出したベースラインは十分な精度とは言えず、改善の余地がありました。ベースライン算出のためのGNSS関連の元データを使って自力で再構成することで、ベースラインを改善することができました。こちらのnotebookをベースにベースラインの再構成を検討していきました。
位置算出に用いる人工衛星の選択
GNSSは、複数の人工衛星からの信号を元に位置測位を行います。ある条件下の人工衛星からの信号は誤差要因となる可能性があるため、これを除外することで位置測位精度が高まる可能性があります。 ホストのベースライン算出時もいくつか人工衛星を選択するフィルタ条件がありましたが、これに条件を追加しました。
具体的には、仰角(ElevationDegrees)によるフィルタ条件を追加しました。仰角が浅い人工衛星からの信号は大気遅延の影響や遮蔽物の影響を大きく受けます。 これらを除外するために仰角で閾値を設定し、閾値以下の人工衛星からの信号を使わないようにしました。その他信号のSN比などいくつかの変数を条件にしてoptunaでチューニングを回しました。
搬送波位相を用いた疑似距離のノイズ軽減
GNSSは人工衛星と受信機の距離を元にして位置測位を行いますが、この人工衛星と受信機の距離算出には2つの方法があります。
一つは信号が到達するまでにかかった時間を元に距離を算出する方法(コード測位)、もう一つは信号の位相を元に距離を算出する方法(搬送波測位)です。
前者はノイズが大きいが絶対距離が容易に算出可能という特徴があります。ベースライン算出にもこちらが用いられています。後者はノイズが小さいが絶対距離算出が難しいという特徴があります。

搬送波測位で算出された距離は相対的な変化量であれば容易に使用できるので、コード測位で算出した絶対距離を、搬送波測位で算出した相対距離で補正を行います。具体的には、[元々のコード測位での絶対距離]と、[搬送波測位で算出された距離の変化量+一時点前の絶対距離]の重み付き平均を取る事でこの補正を行いました。 搬送波位相で算出された距離は、AccumulatedDeltaRangeMeters(ADR)という変数で格納されています。ADRは搬送波位相で算出された距離の差分の積算値なので、この差分を取ることで距離の変化量が得られます。ただ、遮蔽物などで信号を見失う等する(サイクルスリップ)とこの積算値がゼロリセットされるため差分値に大きな誤差が生じる点に注意が必要でした。AccumulatedDeltaRangeStateという変数がビットマップでサイクルスリップ、カウントリセットなどの状態を保持していました。この辺りのすべてのステータスは吟味出来なかったので、一番正常状態と想定されるstatus = 25の時のみ補正を行うようにしました。

その他の公開notebookからの変更点
距離補正項の一つ、[IsrbM]は性質からして固定値であるべきと考え、中央値の定数で置き換えました。いくつかのエリアではこれにより顕著に精度が改善しました。
相対座標の推定
少し前に開催されていたindoorコンペでもそうだったように、outdoorコンペも相対座標による絶対座標の補正が有効では、と当初からdiscussionなどで議論されていました。indoorの時と同様、加速度センサなどのIMUセンサのデータが存在するため、これらのデータから相対座標を推定することができるのでは、と思われていました。しかし、indoorほどそれは容易ではなかったようです。indoorコンペに参加していないので詳しいことは分かりませんが、indoorの時は人間が持って歩いているため加速度センサなどに特徴的なパターンが生じるのに対して、今回は車両に固定されているため特に距離の推定が難しかったのではないかと思います。
このように相対距離を精度よく推定するのが中々難しいという課題がありました。これを解決する手段もGNSSにありました。
ドップラーシフトを用いた車両速度推定
人工衛星と車両の相対速度によって搬送波位相のシフト(ドップラーシフト)が発生します。このドップラーシフトから車両の速度が高精度に推定することができました。
人工衛星・車両の位置、人工衛星ー車両間の距離、人工衛星の速度、ドップラーシフト量がわかれば、車両の速度を推定することができます。
参考文献
人工衛星の位置・速度はGNSSの信号のなかに情報として含まれています。車両の位置、人工衛星-車両間の距離は、位置測位の算出結果によって得ることができます。なので位置測位を行ったのち、その結果を用いて再度車両速度を求めるための計算を行います。
ドップラーシフト量はPseudorangeRateMetersPerSecondとして格納されているのでこれを用います。PseudorangeRateUncertaintyMetersPerSecond を最小二乗法の重みとして用いました。
これによって得られた車両速度は非常に高精度であり、x, y, z成分で与えられるので、緯度経度それぞれの変化量も高精度に算出可能です。これは非常に有用でした。
車両速度+IMUでの相対位置推定モデル
ドップラーシフトから求めた車両速度と、そこから計算した相対位置は非常に高精度ですが、いくつかの時点で欠損が見られました。この欠損の補間のため、IMUセンサのデータも加え、相対位置推定モデルを作成しました。車両速度、各種IMUセンサのdiff、rolling系の特徴量を追加し、計500程度の特徴量を用いてLightGBMにて経度と緯度それぞれの変化量を予測しました。

異常値除去
ホストのベースライン、および再構成したベースラインにはいくつか異常値が見られました。これを除去していきます。
瞬間移動の除去
時々、大きく座標がジャンプしている箇所がありました。これについては一つ前と一つ後の相対移動距離を算出し、そのどちらもが閾値を超える点を異常値として除去しました。この方法で明らかな異常値をいくつか除去できますが、異常値が連続して出現する場合や微妙な異常値には対応できず、後述する異常値除去が重要となりました。
ground truthを元にした異常値除去
いくつかのエリアはtrainとtestで走行経路が一致していました。そのため、trainの正解データ(ground truth)を元に異常値除去を行いました。各trainデータに対して、全てのground truthとの距離を算出し、最近接距離が閾値以上の点を異常値として除去しました。
相対座標から算出した基準点を元にした異常値除去
多くのエリアはtestがtrainでは登場していない経路を辿っていました。そのようなケースでは前述した、ground truthを元にした異常値除去が使えません。
この解決策として、相対座標から基準点を算出し、これを元にして異常値を抽出しました。相対座標は精度よく算出できているので、短い期間であれば積算値で妥当な絶対座標を求めていくことが可能です。各時刻の絶対座標を始点として前後60秒の時刻の絶対座標を始点の絶対座標+相対座標の積算値により算出しました。このウインドウをスライドさせていき、同様の処理を繰り返します。これによって、各時刻ごと、「どこかの絶対座標+相対座標の積算値」で算出された座標が60~120点程度得られます。この座標の精度は始点の絶対座標の精度に大きく依存し、場合によっては始点の絶対座標が除外したい外れ値となるケースがあります。ただ発生頻度は高くないので、各時刻で得られた60点以上のデータの5〜95%点のデータを取ることで外れ値を除外することができると考えました。これによって、各時刻ごとの基準データが生成されますので、この平均+2σを異常値判定の閾値として設定しました。全体的にばらつきが発生している点はσの値が高くなり閾値が甘くなる一方、ばらつきが少ない期間ではσが小さくなるため、閾値が厳しくなります。このように区間ごと動的に閾値が調整されることがメリットです。

閾値設定および補間の考え方
上記の異常値除去は閾値設定のパラメータがそれぞれ存在しますが、基本的にはCVスコアを元に算出し、補間には線形補間、または相対座標の積算により補間を行いました。どちらの補間方法とするかはエリアごと設定しました。異常値が連続して発生する市街地エリアは相対座標による補間、ほぼ一点だけ単独で発生するエリアは線形補間で良好な結果が得られました。おそらく基本的に車は直進しているので、単独点の補間は線形補間で十分だったと推測します。何れにせよ、欠損値は妥当な補間ができると踏んでいたので、異常値のオーバーキルはあまり気にしていませんでした。
後処理
得られた絶対座標のデータに対して、スムージングや補正など様々な後処理を加えていきます。ほかの方のソリューションを見ると非常に創意工夫が見られるパートですが、時間が足りずあまり力を掛けられませんでした。
停止期間の処理
こちらのnotebookでも触れたのですが、車両が停止している期間は座標の誤差が大きくなる傾向が見られました。

これについては、IMUセンサデータなどから停止状態を推定するモデルを作成し、停止状態と判定された区間の座標をその間の平均値で置換するという処理を行いました。データを見る限り、バラつき方にはそれぞれバイアスがあるように見えたので平均値での置換でよいのか、という疑念はあったのですが、結局代替案を検討する時間がありませんでした。
cost minimization
相対座標と絶対座標を用いて最適化を行います。こちらはindoorコンペで広く使われていたsaitoさんの神notebookを使わせていただきました。
weighted phones mean
一つの車両に複数台のスマホが設置されているケースが多いので、この複数台のスマホの推定座標の平均値を求めて最終的な推定値を算出します。これはコンペ序盤にこちらのnotebookで共有したもの*1です。最終的にはこれを改良し、スマホの機種ごと重み付けをできる形にしました。trainのデータを元に機種ごとの重み付けを調整しました。
その他
完全にそのまま流用したもの
カルマンスムーザ
position shift
エリアのグルーピング
前述のとおり、高速道路と市街地では大きく位置測位の精度が異なります。これらエリアの特性ごと処理やパラメータを調整することも重要でした。
エリアのグルーピングには、こちらのnotebookを参考にさせていただきました。このnotebookに、trainとの一致度の要素を追加して計5つのグループに分けました。各グループごとパラメータチューニングや処理の順序など調整しました。
解法のポイント
解法説明の文量から分かるようにGNSS関連のアプローチに中盤以降、多くの時間を割き、スコア向上につなげることができました。特に、ドップラーシフトによる相対座標算出を実現できたのが大きかったと思います。これによって、異常値除去やcost minimizationでのスコア向上につなげることができました。
また、相対座標を用いた異常値除去は終盤土壇場で取り入れたのですが、これも最後の一押しに有効でした。ground truthを元にした異常値除去が適用できるエリアはスコアが悪くインパクトも大きかったので、その他のエリアへの異常値除去に目が向いていなかったのですが、このdiscussionをきっかけに必要性を意識*2し、取り込みました。
コンペ期間の振り返り
twitterでのつぶやきを頼りにコンペ期間をどう過ごしたか振り返りたいと思います。
コンペ序盤、phones meanで金圏に。併せてnotebookを公開した。公開したnotebookを丸コピされたので圧を掛けて消したりした。公開するために、ローカルのコードをkaggle notebook上で再現したらスコア上がった。なぞい pic.twitter.com/suJvTAVm0O
— T88 (@take213) 2021年6月2日
最終的にprivate1位だった、taroさんが圧倒的なスコアをたたき出した瞬間。outdoor、3.X台が出ている...
— T88 (@take213) 2021年6月15日
うわあ、抜かれてる。。。
— T88 (@take213) 2021年7月12日
こんなんあと24日も続けるのか。身と心が持たない
中盤以降は金圏ボーダーが主戦場だったのでだいぶ精神的にやられてくる。妻にはなんかずっとブツブツ言ってるよ、と指摘されたりした。
「綱渡りだな」
— T88 (@take213) 2021年7月25日
「この先、ずっとそうさ」
ハサウェイにはまる。
危惧はしていたが土壇場チームマージ勢の追い上げがきつい
— T88 (@take213) 2021年7月28日
締め切り間際のチームマージによる加速に焦る。
オープンエア pic.twitter.com/mF70pvBsjx
— T88 (@take213) 2021年7月31日
コロナの影響で週末は子供を公園に連れていくことが多かったが、開放的な空間でも常にGNSSが脳裏にちらついていた。
豊國神社で必勝祈願した
— T88 (@take213) 2021年7月31日
大阪城公園の中にある豊國神社で必勝祈願。お賽銭に1000円投入した。
妖怪スコア隠しが出たぞー
— T88 (@take213) 2021年8月3日
お願いしますね、ほんと pic.twitter.com/4VoBHQl5th
— T88 (@take213) 2021年8月3日
2位に突如として現れた専門家に焦る。indoorの時のようにスコア隠しが出たらどうしよう、と怯える。願いをチーム名に込める。
いちおう3.4X台に突入した。もう寝ます
— T88 (@take213) 2021年8月4日
3.4Xに到達し、フィニッシュ。
おわりに
今回の結果でmasterに昇格することができました。

ASHRAEコンペから本格的にkaggle参加して約2年。まさか自分がmasterに昇格する日が来るとは、しかもそれがソロ金で、というようにだいぶ驚いています。今後はいろいろな方とチームを組んで学ばせていただけたらよいなと思っていますので、皆さんよろしくお願いします。
とはいっても、この2か月あまり、かなりkaggle重視でやってきて、いろいろ他のことが疎かになっているので、まずはそのケアをするために暫くkaggleはお休みしようかなと思っています。(と言いながら次のコンペの出現を待つ日々)
kaggleコンペ「Riiid! Answer Correctness Prediction」に参加しました
10月6日から1月7日まで開催されていたkaggleの「Riiid! Answer Correctness Prediction」に参加しました。全3,406チームが参加した中で、publicLB59位 / privateLB63位で銀メダルを取得することができました。初の銀メダルということで大変嬉しいです。

上位にはたくさんの日本人kagglerの方々がいる中でどこまで有用か分かりませんが、自分のメモとして取り組み内容・解法を簡単にまとめたいと思います。
コンペの概要
TOEIC学習アプリのログデータを元に、将来のユーザの正解/不正解を予測するタスクです。評価指標はAUCでした。
学習用データ
学習に用いるデータは下記の通りでした。
- train.csv
- questions.csv
- lectures.csv
train.csvがメインのデータで、ユーザ行動のログです。ユーザの行動には、「問題に回答」「講義を見る」の2種類があり、questions.csvとlectures.csvに問題と講義のメタデータが格納されていました。このうち、予測対象なのは問題の方ですが、講義の閲覧履歴も副次的な情報として利用が出来ました。
データ項目としては、下記の通り(抜粋)。
<train.csv>
- 正解/不正解
- ユーザの回答
- 問題/講義のID
- timestamp(各ユーザごと開始を0とした相対値)
- 前回の問題の回答時間
- 前回の問題の解説を見たかどうか
<questions.csv>
- 問題の答え
- TOEICのPart
- Tag
<lectures.csv>
- TOEICのPart
- Tag
- 講義の種類
データ項目としてはそこまでリッチではないですが、一方で40万人近くのユーザの行動ログが合計100Mレコード程度ありました。
テストデータ
テストデータはファイルとしては提供されずに、Time-series APIによって出力されました。このAPIの出力データはnotebook上ではごく少数のサンプルデータしか見る事が出来ず、submitすることによって内部で処理が走り全データの推論が行われる仕組みでした。APIによる出力は時系列の順番を保って順に出力されます。
テストデータは時系列上、trian.csvの後に位置し、合計2.5Mレコード(前半20%がPublic/残りがprivate)でした。trainで登場している既存ユーザとtestで新規に登場する新規ユーザ両方が含まれていました。
コンペの特徴
Time-series APIによるテストデータ出力が今回のコンペの特出すべき点だったと思います。時系列に沿ってデータが順次出力されるので、これらの情報を元に推論フェーズの中で特徴量を更新していく必要がありました。testのデータ数はそこまで多くないですが、iter回数が膨大なので、何も工夫せずに処理を組むと普通に9時間を超えErrorになってしまいます。この点はこのコンペの難しい部分ではありましたが、一方でコンペを現実世界の問題に近づけ、競技性も高めており、非常に良い仕組みだったと思います。
解法
このdiscussionでも共有されているようなTransformerベースのモデルを使っているチームが多かったと思いますが、僕はGBDTで取り組みました。途中でGBDTでの限界を感じ、Transformerモデルの検討を考えましたが、時間・スキル面でそれが叶わず、GBDTで走りきる形になりました。
validation
こちらのtitoさんのnotebookを利用させて頂きました。
元々のtrainデータはユーザでsortされているため、そのままの並びで分割してしまうと、validがほぼ新規ユーザになってしまうため適切ではありませんでした。またデータのtimestampは各ユーザごとの相対値のため、これを用いることもできません。この解決策として、上記のnotebookではユーザごとランダムなoffsetを加算したtimestampを作成しています。こうすることにより、仮想的にtimestampを絶対値として取り扱うことができ、この値でsortしたデータを任意に分割することで良い感じにvalidationを切ることができました。
model
下記モデルのアンサンブル
- LightGBM(全データ) SeedAvg×3
- LGB + CAT stacking(valid:0.90-0.95)
- LGB + CAT stacking(valid:0.95-)
推論フェーズでの時間制限がシビアなため多種多様なモデルをアンサンブルすることは難しく、同一の特徴量セットを用いてvalidの切り方やモデル種を変更した複数モデルの平均を取りました。ただ、アンサンブルでの伸びはあまりなく、単体0.800→アンサンブル0.801でした。
特徴量
大別すると、「質問に関する特徴量」と「ユーザに関する特徴量」を作成しました。元々のデータ項目と併せて計87個の特徴量を使用しました。

<質問に関する特徴量>
- questionsのtag(listを個別に分解 tag1 - tag6)
- トータル回答回数 / 正解数 / 正答率
- (各ユーザ初回の)トータル回答回数 / 正解数 / 正答率
- (各ユーザ2回目以降の)トータル回答回数 / 正解数 / 正答率
- elapsed_timeの合計・平均
- had_explanationの合計・率
- 同一bundleでの正答率平均
<ユーザに関する特徴量>
- トータル回答回数 / 正解数 / 正答率 (全体&part別)
- 前回のtimestampとのdiff
- 一つ前の正解/不正解のtimestampとのdiff
- その問題を過去に何回解いたか
- その問題を正解したことがあるか
- 以前解いたことがある問題の正答率
- 回答頻度 (回答回数とtimestampの割り算)
- 質問正答率の平均(全て / 正解のみ / 不正解のみ)
- 前回の質問正答率とのdiff
- 直近5回分のtimestamp_diff / answered_correctly / part / 質問正答率
- lectureの総受講回数
全ユーザの回答結果を用いて算出した質問ごとの正答率はその問題の難易度を示すものとして有用でした。同様にユーザごとの正答率は、そのユーザの能力を示す指標となります。また、同一の問題を同じユーザが何度も解くケースが見られました。このようなケースでは当然正解する可能性が高まりますので、繰り返しかどうかというのも重要な情報でした。これらの組み合わせで、各ユーザ2回目以降の回答での質問ごとの正答率、ユーザごと正解した問題の質問正答率の平均、というような形でケース別の特徴量を生成していきました。
また、題材となっているアプリにおいて既にAIチュータによる問題の出し分けが行われていると考えると、ユーザに対して問題が簡単過ぎれば難易度を上げ、難しすぎれば難易度を下げ、という形で調整が行われていると想定しました。このような動きのどの局面にいるのかを表現することを狙いとして、質問正答率のdiffやshiftを作成しました。
diff、shift系の特徴量はかなり有用で、timestampのshift系の特徴量も寄与が大きかったです。同日に連続して解いている途中なのか、それとも間を置いて取り組んでいるのかを示す有効な特徴量として機能したのではと思うのですが、寄与度から考えるにそれ以上の何かがあるのかもしれません。shift量に関して直近5回というのは感覚的に短期すぎる気がしていますが、cvの結果を元に決定しました。
長期的な傾向を大まかに示す平均系の特徴量と、短期的な傾向を詳細に示すshift,diff系の特徴量という棲み分けをイメージして検討していました。attentionを用いると長期的な関係性をもっと上手く表現出来て、それが0.8以上の領域の鍵なのかなと勝手に想像しますが、全然分かってません(solutionで勉強させてもらいます。)
試したが上手く行かなかったアプローチ
全体的に混み入った特徴量はことごとくうまく行きませんでした。
- questionのグルーピング(TAGベース、2つの質問間の連関係数、難易度のrank化など)
- 直近のlecture受講とのtimestampのdiff
- 各ユーザごと1番最初のquestion_id
- 各ユーザごと先頭30問の成績
- ユーザrating(質問難易度を加味したスコアリング)
- timestampをdayに変換し、dayごと集計
直近のlecture受講とのtimestampのdiffは、cvでは+0.001程度効いていたのですが、LBスコアは低下しました。
合計の回答数が30のユーザが突出して多いことから、最初の30問はアプリ利用開始時のユーザ能力測定のための問題セットと考えました。また、この前半30問は決まった問題が出力されることが多そうだったので、この先頭30問をユーザの初期能力として特徴量を作りました。がこれもうまくいかず。
その他、questionをグルーピングしたりユーザのratingスコアのようなものも検討しましたがうまくいかず。これらのアプローチがダメというよりは適切に落とし込みができなかったような気がしています。
具体的な取り組み方
特徴量検討
全データを用いると加工や学習に時間が掛かりすぎるため、全体の10%のデータで特徴量の検討を行いました。
データ加工処理
今回のコンペでは、一方で100Mレコードの学習データを一気に処理する、もう一方で小数のテストデータを元に特徴量を逐次的に更新する必要がありました。そのため、同じ特徴量でもtrainとtestで別々の処理を実装しました。
trainについては、pandasのgroupby+cumsum/cumcountやshift、fillna(method='ffill')などを使って、各レコード時点の特徴量を生成しました。
train終了時点の情報を元にuser_idをkeyとする特徴量算出のための情報を集めたテーブルを作成し、これをtestフェーズで順次更新する処理を実装しました。更新するのはユーザに関する情報のみで、質問に関しては一貫してtrain全体で算出した特徴量を用いました。train/testの比率から影響は軽微と考え、処理時間短縮のためにこのようにしました。
testフェーズの特徴量更新処理のテスト
上記のように、trainとtestで別々の処理を実装しますが、当然最終的な出力は一致させる必要があります。ただ、testの処理は秘匿化されており、その結果であるpublicLBのスコアでしか処理の正しさを推し量れません。これでは仮にcvとpublicLBの乖離が発生した時に、それが追加した特徴量自身の問題なのか、その実装に誤りがあるのか切り分け出来ませんし、仮に実装の誤りと考えたとしてもそのバグを潰すために何回もsubするのは非効率です。
この解決策として、trainデータを用いて推論フェーズのシミュレーションを用意しました。これまたtitoさんのこちらのnotebookをマイナチェンジして用いました。
trainのデータ処理を行いその後分割したvalidデータと、シミュレータによって逐次的に処理したvalidデータ、両者でスコアが一致するか / 各特徴量が一致するかを検証しました。このテストを特徴量を増やす度に実行してバグ取りを行いました。殆どの特徴量で何らかのバグが埋め込まれていたので、このテストは非常に有用でした。やはりテスト大事。石に刻んでおきたい。
testフェーズの処理時間短縮
%%timeで各処理を時間計測して処理時間の短縮を検討しました。結局は、ユーザ特徴量をuser_idをindexとしたpandasのDataFrameで保持しておき、各要素に対して.at[user_id, 'hoge']でアクセスする形が処理時間的にも実装的にも楽だったので、この形に落ち着きました。
testフェーズのメモリ容量削減
処理時間ほどシビアではないですが、一部工夫をしないといけない点がありました。各ユーザごとその質問をこれまで何回答えたか・正解したか、というのは重要情報ですが、これをそのまま実装すると、40万ユーザ×14000質問の組み合わせとなりメモリ的にかなり厳しいことになります。
これに対処するために、こちらのdiscussionを参考に、user_idをkey,14000個のビット配列をvalueとしたdictを用いました。配列要素一つ一つがquestion_idに対応し、0/1をそれぞれ、問題を解いたことがない/ある、問題を正解したことがない/ある、と捉えることでユーザごとその質問を解いたことがあるか、正解したことがあるかの情報を保持しました。
また、質問に答えたかどうかではなく、その回数まで使うとcvスコアが無視できないレベルで向上したので、こちらは回数まで保持しました。dictの方で0,1回までは切り分けができるので、回答数が2回以上のパターンのみ別で保持するようにしました。(user_id, question_id)のmultiIndexのDataFrameを用いました。
その他
teamとしての取組
今回、比較的素直な題材だったので入門に良いかなと思い、kaggleに興味があるけど参加したことがない同僚を誘ってteamを組みました。
baselineを僕の方で作って、trainでの特徴量検討の部分を各自自由に進めるという形を試みました。連絡にはslackを使い、特徴量の検討状況はスプレッドシートにまとめるという形にしました。ただ年末で忙しかったのか、はたまた題材が悪かったのか、フォローが足りなかったのか、全員脱落してしまって、気付いたらソロで戦っていました。
分析コンペでの学びは大きいと思うので引き続き布教・勧誘・拉致に励みたいと思います。
今後の取組
この記事でも書いた通り、ローカルマシンを購入しました。この投資回収の意味も込めて今年中にはmasterになりたいと思っています。
圧倒的にNN力が不足しているので、まずはCASSAVAコンペでpytorchの練習をしたいと思います。対戦よろしくお願いします。
2020年を振り返る
今年も残すところあと1日。簡単に今年を振り返りたいと思います。
仕事
商品開発からIT・データ分析の組織に異動して、早いものでもう3年経ちました。
知らない間にチームでは割と古参になっていて、年齢的な面とも相まってリーディング・マネジメント的な役割を徐々に求められていることを感じています。
仕事内容としては、基盤・システム開発のPM的なロールを今年初めから担っていました。
これは色々と大変で辛いこともありましたが、言ってしまえば商品開発と似たようなタスクで過去の経験値がそれなりに活きました。
夏頃は、この案件プラス、息の長い分析支援案件やプリセ的な案件など平行で4つくらい動かす必要があってだいぶ頭がパンクしてました。
今はだいぶ落ち着いている、と言うか若干余裕があるので新年からは色々と仕込みが出来たらと思っています。
今年はチーム全体のスキル強化にも取り組んだ1年でした。
2019年後半にうちのチームにいたエース級の同僚が転職してしまって、データ分析のベテラン不在の状況でした。この状況への課題認識がチーム内で一致していたので、自主的なスキル強化活動をいくつか走らせました。
統計学の輪講や分析手法の調査・研究に関する活動は何だかんだ継続することが出来ました。最近ではナレッジマネジメントの仕組みとして、OSSのknowledgeをサーバに構築して試行しています。
information-knowledge.support-project.org
こういう自主的な活動は各人で取り組みの比重がマチマチにはなりますが、あまり強制はせず、それでいて廃らせないように続けていけたらと思います。
今年を語る上で外せないのは、新型コロナウィルスだと思います。
僕も4月以降、ほぼ在宅勤務で仕事をしています。個人的にはこれはかなり助かっています。何より通勤がなくなり可処分時間が増えたことが大きいです。
客観的にみてパフォーマンスも維持できていると思うので、コロナ収束後も在宅中心で働けたら良いと思っていますが、こればかりは会社がどう動くかですね。
kaggle
データ分析の組織にいながらMLモデル構築をする機会が少なく、何とかスキルを身に付けたいなと思いkaggleに参加しました。
ASHRAE, Ion, OpenVaccineで銅メダルを取り、今年の目標にしていたCompetition Expertになることが出来ました。

子供が3歳と1歳で日中や休日に時間を取ることが難しいですが、幸い在宅勤務で通勤がなくなったので、早朝に時間を取って少しずつやっています。
一つのコンペに初期から継続してコミットすれば、何とか戦っていけるだけの時間は確保できることがわかりました。
徐々に戦い方も分かって来て、コンペの中盤では銀圏くらいに位置できるようになって来ましたが、終盤はズルズルと順位を落としてしまいます。これは完全に言い訳出来ない実力の不足です。
最近、ローカルマシン(5950X / RTX3090 / RAM128GB)を購入して、リソース面での言い訳も効かなくなりました。

言い訳の芽を摘み取って純粋に自分の力不足と向き合いつつ、来年のMaster昇格を目指して引き続き精進したいと思います。
資格
統計検定準1級 or 1級取得を目標に掲げていましたが、結局試験が中止になっていました。
今年は、IPAのプロマネに受かったくらいが進捗です。
元々、未経験の分野への異動ということで基礎的なスキル充足の手段として資格を手当たり次第、色々取りましたが、もうそういうフェーズでもないかなと感じています。
とはいえ、統計検定については来年もチャレンジ&IPAは小遣い目的で受験しようかな、と思います。
生活
子供が順調に成長してます。それは大変喜ばしいですが、負荷も線型的に増加しているという実感です。
余裕がないとつい感情的に叱ってしまうなど、自分自身が如何に子供か思い知らされる機会が多いです。
月並みな言葉ですが、子供と一緒に成長していけたらと思います。
健康面ですが、体重増加が大変まずいです。リングフィットと散歩で減量を図っていきたいと思います。
おわりに
年の瀬だからか、何だか非常に真面目な感じになってしまいました。
改めて振り返ると鈍足ではありますが、少しは前進できた1年だったかなと感じています。来年も無理のない範囲で自分が納得できるような進捗を生み出していきたいと思います。
IPA プロジェクトマネージャ試験に合格しました
令和2年度のプロジェクトマネージャ試験に合格しました。
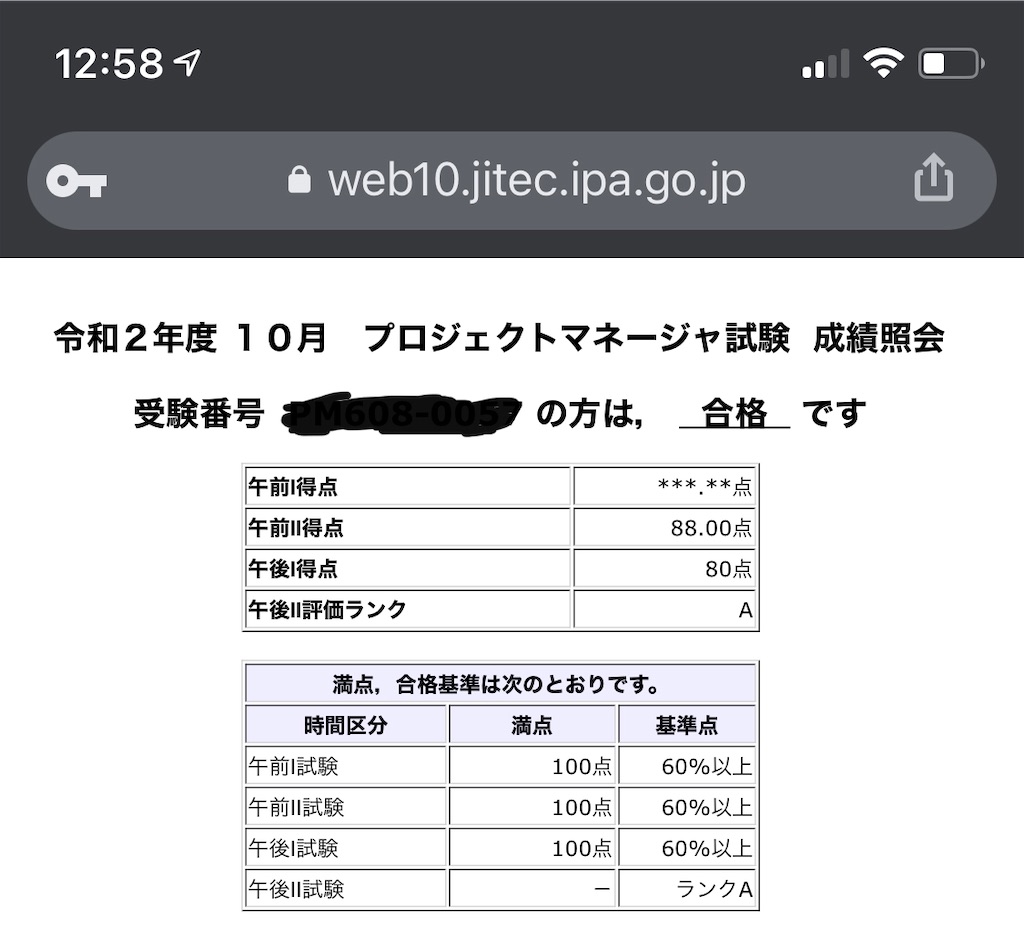
前回(平成31年度)のリベンジが果たせました。
IPA プロマネ落ちました - the invention of t88
例によって、学習方法やコツについてまとめたいと思います。
プロジェクトマネージャ試験とは
システム開発計画を円滑に運営する責任者、いわゆる(役割としての)プロジェクトマネージャを対象者とした国家試験である。
-- 中略 --
プロジェクトマネージャの社会的な需要は高く、ITPro(日経BP)の調査では、「技術職の社員に取らせたいIT資格」として2006年版以降毎年第1位となっており[1]、IT業界の花形資格と言われることも多い。 -wikipedia
システム開発のプロマネに関する国家試験です。会社によっては昇格要件になっているところもあるそうで、それなりに知名度がある資格だと思います。難易度としては、IPAの高度試験の中でも比較的難関なようです。(が個人的にはネスぺの方が大分キツかった。)
参考書

この試験の鉄板、通称みよちゃん本を使いました。
ちょっと暑苦しいですが、解説がしっかりしています。何より過去15年以上の過去問と解説がDLできるのが非常にありがたいです。
参考書はこの本一冊で問題ないと思います。
各パート
試験は、午前1・2、午後1・2の4パートに分かれています。
このうち、午前1は過去2年間で応用情報や高度試験を合格していれば免除されますので、実質的には午前2からのスタートとなる事が多いと思います。
午前2
選択問題で、しかも半分以上は過去に出題された事がある問題なので非常に容易です。下記サイトをひたすら周回して脳に刷り込んでおけばokです。
プロジェクトマネージャ過去問道場|プロジェクトマネージャ試験.com
午後1
プロジェクトに関する記述を読んで、それに関する質問に答える問題です。大問3問から2問を選択します。
問題はほぼ記述式ですが、何か知識がないと答えられない問題は少なく、多くは問題の文章中に答えがあります。個人的には午後1は非常に簡単に感じました。
過去問をさらっと解いてみて余裕そうであれば、午後1の対策に掛ける時間を全て午後2に費やす方が合格に近づくかもしれません。
午後2
この試験最大の鬼門です。
大問2問から1問選択して、問題文の記述に沿って自分の担当したプロジェクトに関する論文を書きます。文字数はトータルで2000字以上。
午後2への対策が合否の鍵を握ると思っていますので、この部分を詳細に説明します。
午後2攻略法
題材となるプロジェクトの具体化
論文を書くにあたっては、題材となるプロジェクトが必要です。
このプロジェクトを予め構想しておく必要があります。この際には、大まかな線表、体制、コストのレベルまで具体化しておくと良いです。また想定される問題に応じてフィットするプロジェクトの形は変わりますので、複数パターン用意しておけると対応力が増します。
何かしらのシステム開発やPM業務に携わった事があれば、実例をマイナチェンジして対応が可能ですが、未経験だと仮想のプロジェクトを1からでっち上げる必要があります。これはかなり困難です。
この場合は、どこからか情報を拾い集める必要があります。幸い、午後1の問題は多種多様なプロジェクトに関する具体的な記述が為されていますので、ここから情報収拾するのが良いのではと思います。
このように題材となるプロジェクトの正常系(何も問題が起きなかったケース)を準備しておいて、これを下地にあとは問題文のテーマに応じてリスクや問題発生を差し込んでいく、という形になります。
試験準備
まずは過去問の問題文と解答例をさらっと見てみて雰囲気を掴みます。その上でなるべく早期に、実際に問題を2時間掛けて解いてみることをオススメします。
解答例をさらっと見ると割とイケそうな気配を感じますが、実際に書いてみるとかなり難しいです。まず2000字以上書くのが肉体的にしんどい...。
これを早めに行うことで合格のために埋めるべきギャップが明確になります。
あとは、ただひたすら過去問を解いていきます。全ての問題で実際に2h掛けて記述するとロスが大きいので、実際に解く / 内容の骨子だけ作成する / 解答例を見るだけ という形で取り組み方に強弱を付けるのが効率的だと思います。何回か実際に解いて骨子が適切に文章として出力できるレベルになったら、あとは骨子作成に留めておいて数をこなすイメージです。
回答の仕方
合格するためには高尚な内容は不要です。一番重要なのは問われている問題に適切に反応することです。設問だけでなく上部の問題文の記述をよく読み、求められている要素を適切に論文に落とし込んでいく必要があります。
試験時の流れとしては、問題文を読み求められている要素を洗い出す。その上で記述内容の骨子を作成する。これらを最初の15~20分程度で行った上で実際に回答を行うと良いと思います。
注意する点
あくまでPMというロールなので、実際に自分で手を動かしたような記述はマズイです。何らかの対策は必ずプロジェクトメンバへ指示する、結果をウォッチする、というスタンスで。
さいごに
午後2の論文の対策・回答がかなり苦行なので、ひとまず合格ができてよかったです。苦行ではありますが何となくコツが掴めてきたので、引き続きシステムアーキテクトなど挑戦していこうと思います。
QC検定1級合格記
 2019年9月開催のQC検定1級に合格しました。
2019年9月開催のQC検定1級に合格しました。
8月中旬に第二子誕生などのイベントもあり、なかなか勉強時間が取れませんでしたが何とか合格。結局、本腰を入れて勉強出来たのは一週間程度でした。

あくまで学習のモチベーション維持のために資格を受けてるのですが*1、今回は準備期間があまりに短かったので、かなり試験合格に最適化してしまいました。恥ずかしながら。
やんごとなき事情でどうしてもQC検定1級に合格しないといけない、という人もいるかもしれません。そういう方に役立つことを期待し、合格記としてまとめたいと思います。
QC検定1級とは?
品質管理に関する知識について評価する検定です。
1級はこの最上級に当たります。
試験範囲

工場のマネジメントに関することから、一通りの具体的な手法まで出題されます。範囲はかなり広め。
試験要項
試験時間 120分:マークシート・論述
合格基準(aかつbかつc)
(a)
一次試験(手法分野、実践分野):各分野の得点が概ね50%以上であること。及び、総合得点(手法分野+実践分野)が概ね70%以上であること。
(b)
二次試験(論述):得点が概ね50%以上。
(c)
総合得点(一次・二次試験の合計点)が概ね70%以上。
このややこしい合格基準がQC検定1級の肝です。
また一次、二次となっていますが試験時間が分かれている訳ではなく、全て120分の中で解く必要があります。
試験攻略のポイント
QC検定1級は大きく分けて3つのパートに分かれます。
①マークシート(手法分野)
具体的なQC手法についての計算問題
②マークシート(実践分野)
QC活動に関する語句問題
③論述
与えられた題目に関してA4 1枚で論述
合格する為には
①②③それぞれで50%以上
①+②が70%以上
①+②+③が70%以上
である必要があります。
この合格条件を達成する事を意識して、準備に費やす時間や試験中の時間配分のリソースを考えることが重要です。
特にマークシートの①手法と②実践がポイントです。
①手法は範囲が広く、各々の問題で割と突っ込んだことを聞かれます。多くは計算問題です。中々の高難易度です。
反面、②実践は語句を暗記していれば簡単に90%程度は取れます。
①手法だけ見るとかなり高難易度なのですが、②実践でカバーできれば5,6割程度が合格ラインとなります。
最小のリソースで②実践で高得点を取りつつ、①手法の凹みをカバーすることになるでしょう。
勉強方法
1週間コース
私の場合は、1週間程度しか残り時間がなかったので下記の参考書1冊に集中しました。
")
【新レベル表対応版】QC検定1級模擬問題集 (品質管理検定講座)
- 作者: 細谷克也,岩崎日出男,今野勤,竹山象三,竹士伊知郎,西敏明
- 出版社/メーカー: 日科技連出版社
- 発売日: 2016/12/20
- メディア: 単行本(ソフトカバー)
- この商品を含むブログを見る
各単目ごと複数の出題パターンが掲載されているので、網羅性が高いです。解説がしっかりされているので副読本なしでも学習を進めていけます。
特出すべき点として、この本には論述の問題も掲載されています。論述については参考情報があまりないので、これは大変助かりました。
ざっとまずは順繰りに解いていき、その後、手法分野の解法パターンを頭に刷り込ませました。論述についてはあまり時間が取れず、当日の午前に問題と模範解答を読んでイメージを作っていきました。
結果としてこのリソース配分は正解だったように思います。手法分野に多くの時間を割くのが良いでしょう。
じっくりコース
しっかりと準備期間を取って勉強しながら資格取得を目指したい、またはあまりQC分野に明るくないという方向けの勉強方法も考えてみました。
まずは読み物でQCについて理解する。大村平さんの下記シリーズは大変読みやすいです。

- 作者: 大村平
- 出版社/メーカー: 日科技連出版社
- 発売日: 2014/01/01
- メディア: 単行本
- この商品を含むブログを見る

- 作者: 大村平
- 出版社/メーカー: 日科技連出版社
- 発売日: 2013/01/01
- メディア: 単行本
- この商品を含むブログ (1件) を見る
あとは、上の1週間コースで挙げた模擬問題集にプラスして下記を解く。

- 作者: QC検定過去問題解説委員会,仁科健
- 出版社/メーカー: 日本規格協会
- 発売日: 2019/07/29
- メディア: 単行本
- この商品を含むブログを見る
 QC検定試験1級対応")
2015年改定レベル表対応 品質管理の演習問題と解説(手法編) QC検定試験1級対応
- 作者: 新藤久和
- 出版社/メーカー: 日本規格協会
- 発売日: 2015/12/11
- メディア: 単行本(ソフトカバー)
- この商品を含むブログを見る
1つ目は過去問題集、2つ目は手法分野に特化した問題集です。たくさんの問題に触れて引き出しを増やしておくと良いと思います。
そもそも論として、じっくりやりたかったらまずは2級から取得するのが良いかもしれません。
試験本番
とにかく時間配分が大切です。
じっくり解いていくと120分は確実にオーバーします。手法分野は計算問題なので、すぐに解答は思い浮かばないがじっくり考えれば分かりそう、みたいな問題が結構あります。実践分野は選択肢の中に似たような単語があって、どちらが適切か迷う時があります。これらに気を取られて時間を掛けてしまうと時間overで詰みます。手法分野、実践分野、論述に掛ける時間を予め決めておき、それに沿って解いていきましょう。
順番としては、実践→手法→論述→手法の順番がオススメです。
実践は簡単なのでスラスラ解けます。勢いを付けるのに良いです。この時点で120分というとかなり時間があるように感じますが、全然時間はないのでスピードを意識しましょう。10~20分くらいで終わらせたいところです。
手法は解ける大問、解けない大問がはっきり分かります。まずは全体をザッと解くことをオススメします。この段階で解けた問題、解けないが時間を掛ければ解けそうな問題、解けない問題に切り分けておくと良いです。残り1時間程度になったら論述に移行します。
残りの1時間で論述に取り組みます。一般論ですが、書き始める前にざっくりとした構成を考えておくと書いている途中で迷子にならずに済みます。
論述終了後、余った時間は手法に戻って、解けないが時間をかければ解けそうな問題中心に取り組みます。また、正しい解答は分からないが確実に間違っている選択肢は除外できる、というケースもあるので、そういったケースの当てずっぽうの的中確率を少しでも高めていく、というのも意外に重要です。ここでの粘りが合否に大きく影響を与えます。
さいごに
QC検定1級に合格するためのポイントを、今回の体験を元にまとめてみました。合格率だけ見るとすごく難関資格に見えますが、ツボを抑えればそこまで合格は遠くないと思います。興味がある方はぜひ挑戦してみてください。
私は、今年中は資格取得はお休みして、データ分析コンペ「kaggle」に挑戦したいと思います。何とかメダルが取れると良いのですが...。
*1:IPAは会社から報奨金が出るのでお金目当て
LOTOの当選結果を自動通知する

少し前からLOTOを購入をしています。
宝クジというとよく「期待値が〜」という声が上がりますが、分散を考えるとそうバカにしたものでもないですよね。300円が数億に化けるなんて事は普通無い。まさに夢を買っていると言えます。
そんなわけで毎回1口ずつ、チマチマと購入して日々のちょっとした刺激として楽しんでいます。
今はLOTO6とLOTO7を買ってます。LOTO6は月木、LOTO7は金、計3回/週、購入しています。購入自体は口座を持っている銀行で定期購入できています。一方で、購入したものが当たったのか、その確認は手動でしないといけません。
この当選確認を自動化したいよね、というのが今回の取り組みです。
pythonで処理作成
WEBから当選結果を読み取る
今回はこちらのサイトを使用させていただきました。 lotonumbers.info

beautiful soupを使ってスクレイピングします。
import urllib.request from bs4 import BeautifulSoup url = 'http://lotonumbers.info/loto6/number/' request = urllib.request.Request(url=url) response = urllib.request.urlopen(request) html = response.read() soup = BeautifulSoup(html)
soupの中身はこんな感じになっています。

thに第何回かの情報が入っています。
tdに当選番号の情報が入っています。
新しい順に並んでいるので、bsのfindで一つ目を抽出してやれば自動的に最新の結果のみ抽出できそうです。
no = soup.find('th').string win_num = soup.find('td').string
win_numは若干ごみが混じっています。

ごみを取りつつ、リストにしておきます。
win_num = win_num.replace('\xa0(',',') win_num = win_num.replace(')','') win_num = win_num.split(',')

本数字とボーナス数字を分けておきます。
win_num_main = win_num[0:6] win_num_bonus = win_num[6]
当選結果を判定する
LOTO6の当選結果は下記の通りです。

単純に本数字とボーナス数字にどれだけマッチしたか、で判別されます。
一致数をカウントし、その数で条件分岐させ、結果を判定します。
my_num = ['01','02','03','04','05','06'] match_main = len(set(my_num) & set(win_num_main)) match_bonus = len(set(my_num) & set(win_num_bonus)) if match_main < 3 : result = 'ハズレ' elif match_main == 3 : result = '5等' elif match_main == 4 : result = '4等' elif match_main == 6 : result = '1等' elif match_main == 5 : if match_bonus == 1: result = '2等' else : result = '3等'
結果をLINEで通知
LINE Notifyを使って通知します。
import requests # LINEで通知 message = \ 'LOTO6 ' + no + '\n\n' + \ '[購入番号]\n' + \ ' '.join(my_num) + '\n\n' + \ '[当選番号]\n' + \ '本数字:\n' + \ ' '.join(win_num_main) + '\n' \ 'ボーナス数字:\n' + \ win_num_bonus + '\n\n' + \ '本数字の一致数:' + str(match_main) + '\n' + \ 'ボーナス数字の一致数:' + str(match_bonus) + '\n' + \ '結果: ' + result url = "https://notify-api.line.me/api/notify" access_token = '**token**' headers = {'Authorization': 'Bearer ' + access_token} payload = {'message': message} r = requests.post(url, headers=headers, params=payload)
参考:
output

コード全体
# パッケージのインストール import urllib.request from bs4 import BeautifulSoup import requests # 自分が購入している番号 my_num = ['01','02','03','04','05','06'] # 当選番号をwebサイトからスクレイピング url = 'http://lotonumbers.info/loto6/number/' request = urllib.request.Request(url=url) response = urllib.request.urlopen(request) html = response.read() soup = BeautifulSoup(html) no = soup.find('th').string win_num = soup.find('td').string # 文字列の整形 win_num = win_num.replace('\xa0(',',') win_num = win_num.replace(')','') win_num = win_num.split(',') # 本数字とボーナス数字に分ける win_num_main = win_num[0:6] win_num_bonus = win_num[6] # 一致数を確認 match_main = len(set(my_num) & set(win_num_main)) match_bonus = len(set(my_num) & set([win_num_bonus])) # 当選結果を判定 if match_main < 3 : result = 'ハズレ' elif match_main == 3 : result = '5等' elif match_main == 4 : result = '4等' elif match_main == 6 : result = '1等' elif match_main == 5 : if match_bonus == 1: result = '2等' else : result = '3等' # LINEで通知 message = \ 'LOTO6 ' + no + '\n\n' + \ '[購入番号]\n' + \ ' '.join(my_num) + '\n\n' + \ '[当選番号]\n' + \ '本数字:\n' + \ ' '.join(win_num_main) + '\n' \ 'ボーナス数字:\n' + \ win_num_bonus + '\n\n' + \ '本数字の一致数:' + str(match_main) + '\n' + \ 'ボーナス数字の一致数:' + str(match_bonus) + '\n' + \ '結果: ' + result url = "https://notify-api.line.me/api/notify" access_token = '**token**' headers = {'Authorization': 'Bearer ' + access_token} payload = {'message': message} r = requests.post(url, headers=headers, params=payload)
AWS lambdaで定期実行させる
先ほどのpythonスクリプトを実行すれば、最新の当選番号と自分の番号を比較して、結果をLINEに通知できます。あとは当選番号の更新が行われるタイミングで定期的に実行すればokです。
ただし、このためだけにPCをスタンバイさせておくのも非常に勿体ないので、AWS lambdaを使ってサーバレスに処理を回したいと思います。
lambdaで処理を実行するに当たっては、使っているパッケージも合わせてupしておく必要があります。下記の記事を参考に、一つのzipファイルに固めてアップロードしました。
参考:
作成したlambdaファンクションをCloudWatch Eventsをトリガーにして、定期実行させます。

実行タイミングはcronで指定可能です。
毎週月木が開票日、データ取得元の更新は遅くとも22時には完了しているだろう、という想定のもと、下記のような条件にしています。
cron(0 13 ? * MON,THU *)
※UTC基準なので-9hした値となっています。
これで完成。
まとめ
LOTO7についてもLOTO6のマイナチェンジで作成しました。
これで完全自動で購入→当選確認ができるようになりました。
あとは果報を寝て待つだけ。

- 作者: Ryan Mitchell,嶋田健志,黒川利明
- 出版社/メーカー: オライリージャパン
- 発売日: 2019/03/26
- メディア: 単行本(ソフトカバー)
- この商品を含むブログを見る
水耕栽培でビートオールレッドを育てる
水耕栽培器にラズパイ+センサ・カメラを取り付け、野菜を栽培しています。
過去記事:
IoT水耕栽培 - the invention of t88
今回はビートオールレッドを育てました。
あまり耳馴染みがないですが、ベビーリーフの1種のようです。
赤い色が特徴的で、ポリフェノールを多く含むようです。


気の利いた調理方法が見つからなかったので、安直にサラダにしました。
適度に苦味があってなかなかに美味しい。

若干、芽が残っていたので収穫後、放置。

次回は実がなる植物を育てます。
【使用している水耕栽培器】

- 出版社/メーカー: ユーイング
- 発売日: 2015/11/01
- メディア: Tools & Hardware
- この商品を含むブログを見る
種子や肥料は公式のオンラインショップで入手可能。水耕栽培が手軽に楽しめます。オススメです。
統計検定2級に受かったので勉強方法を紹介する

先日、6月に受けた統計検定2級の結果がWEBで公開されました。
合格発表は、合格者の番号が掲載されるスタイルです。古き良き感。高校、大学の合格発表的な。
結果ですが、合格してました。
得点はまだ分かりませんが、自己採点の結果通りだとすると69点。やはり当落ラインは公称値の70点より低めに設定されていそうです。
ちなみに合格者の他に成績優秀者がSランク、Aランクに分かれて、発表されています。当然その中には私の番号は含まれていませんでしたが、僕の番号の一個後の番号が載っていました。優秀な方が後ろに座っていたんだなー、顔も見ずでしたが。
さて、例によってなんとかギリギリで合格出来ましたので、簡単に勉強方法など紹介したいと思います。
受験の概要
過去記事でまとめています。 www.t88.work
出題傾向
こちらも過去記事で。 www.t88.work
勉強方法
統計学の素養によって、取るべき初手は変わってきます。
少しでも齧ったことがある場合
少なくとも正規分布や標準偏差、検定推定について一度でも教わった事があるなら、過去問に取り掛かりましょう。
公式HPに過去1回分の過去問が公開されていますが、1回だと少し心許ないです。公式問題集として、過去3年分(計6回)の過去問をまとめたものが販売されていますので、こちらで取り組むと良いです。
![日本統計学会公式認定 統計検定 2級 公式問題集[2016〜2018年]](https://images-fe.ssl-images-amazon.com/images/I/51ra-rJnknL._SL160_.jpg "日本統計学会公式認定 統計検定 2級 公式問題集[2016〜2018年]")
日本統計学会公式認定 統計検定 2級 公式問題集[2016〜2018年]
- 作者: 日本統計学会
- 出版社/メーカー: 実務教育出版
- 発売日: 2019/03/20
- メディア: 単行本(ソフトカバー)
- この商品を含むブログを見る
問題の難易度はそれなりに高く、うろ覚えの知識だと結構難しいと思います。調べながら解いていき、統計学の復習をしつつ、統計検定の問題に慣れていきましょう。ただ、この問題集の解説は大分不親切なので、別途副読書的なものが必要になります。
この副読書ですが、公式のテキストもありますが、あまり評判はよろしくありません。
オススメはこちらです。
")
コア・テキスト統計学 (ライブラリ経済学コア・テキスト&最先端)
- 作者: 大屋幸輔
- 出版社/メーカー: 新世社
- 発売日: 2012/01/01
- メディア: 単行本
- 購入: 1人
- この商品を含むブログを見る
この本は、かなり統計検定2級の出題範囲とマッチしています。記載もわかりやすく、統計検定抜きにしてもオススメ出来る本です。
また、こちらのサイトは、統計に関する解説が充実していて、尚且つ統計検定2級の過去問の解説まであるので、大変有用でした。
過去問を3年分解いて、解説などを見れば何をしているか理解出来る状態になっていれば、当落ラインには達していると思います。
後は暗記的なアプローチにはなりますが、”各分布の期待値・分散”であったり、”検定・推定の解法”について整理し、それを頭に刷り込ませておくと良いでしょう。
統計学に触れた事がない場合
全くの初学者だとすると、統計検定2級は少しハードルが高いのかもしれません。
3級などからスタートするか、もしくは十分な学習期間を設けるのが良いと思います。
学習のステップとしては、上に挙げた試験対策の手前で、統計学の基礎の基礎について学ぶ必要があると思います。
下記書籍はこの導入にオススメです。

- 作者: 高橋信,トレンドプロ
- 出版社/メーカー: オーム社
- 発売日: 2004/07/01
- メディア: 単行本
- 購入: 156人 クリック: 1,757回
- この商品を含むブログ (202件) を見る

- 作者: 小島寛之
- 出版社/メーカー: ダイヤモンド社
- 発売日: 2013/06/17
- メディア: Kindle版
- この商品を含むブログ (2件) を見る
合格のための戦略
どこで点を取るか
大問で15問近くありますが、問題によって難易度が大きく異なります。
初めの方はグラフ読み取り系で非常に簡単です。また、一番最後の方はシミュレーション結果の読み取りが出題されることが多いですが、これもパターンが決まっているので解きやすいと思います。後半の検定・推定も、割とパターンが決まっているので覚えてさえいれば、悩むことは少ないでしょう。
逆に真ん中あたりは結構鬼門です。確率や、分布・統計量に関する問題が出題されますが、素直な問題ではなく、応用的な問題が多いです。
合格のために、まずは前半部分と後半部分では確実に点を取れるようになっておく、のが重要です。この部分は対策しておけば容易に点が取れるのでコスパが高いです。真ん中部分を解き切るのは、なかなか大変なので、若干の割り切りが必要かもしれません。
本番での解き方
よく試験の解き方のセオリーとして言われている事かもしれませんが、解ける問題から解くのが良いでしょう。前半部分と後半部分をまずは解き、その後に真ん中の解ける問題から解いていく、という形になるかと思います。
一点、気を付ける点として、前半部分は非常に簡単なのですが地道な計算作業が必要な問題が結構あります。試験開始間際で残り時間も意識していない段階です。この状態で、こういった問題に当たると検算などでついつい時間を費やしてしまいがちです。ただ、ここに時間を費やしてしまうと後からシンドくなります。時間がたっぷりあるようで、実はそんなにないので、前半部分からスピードは意識する必要があります。
また、真ん中の部分は難易度が高めではあるのですが、大問のうちのいくつかの小問は比較的簡単だったりします。また、選択問題なので、消去法を適用して候補を絞り込む事で、50%程度の運ゲーに持ち込むことができるケースもあります。
要は諦めないことが重要です。残り時間をフルに使って少しでも正解を拾う、というのが合格の可能性を高める振る舞いだと思います。
まとめ
統計の知識を定着化させる意味で、統計検定は非常に有用でした。統計学に興味ある方はぜひ受験をオススメします。その際は、この記事の勉強方法を参考にして頂けると嬉しいです。
さて、来年は、準1級を受けようかな。
関連記事まとめ:
他にも色々と資格取得中です。
www.t88.work
水耕栽培でルッコラを育てる
水耕栽培ですが、ジャーマンカモミールの不発により、代打としてルッコラを育てていました。
今度はちゃんと発芽してくれました。ひょろ長い芽が。

ジャーマンカモミールは種まんまでしたが、これまで無事育ったジェンティリナグリーン、水菜、そして今回のルッコラは全部緑色の糖衣みたいなもので包まれています。結構、この緑色のコーティングが重要なんでしょうか?

それはそれとして、今回も成長の様子をGIFで。

ぐんぐん育ちました。室温が上がってきたので、スポンジにアオコが出来るようになりましたが。

パスタにして食す。美味い。

生でも齧ってみましたが、味が濃く美味しかったです。正攻法でサラダにするのも良いかも。
次回:
ビートオールレッドを育てます。
【使用している水耕栽培器】
- 出版社/メーカー: ユーイング
- 発売日: 2015/11/01
- メディア: Tools & Hardware
- この商品を含むブログを見る
室内でもガンガン野菜が育ちます。
種子や肥料は公式のオンラインショップで入手可能。水耕栽培が手軽に楽しめます。オススメです。
【IoT水耕栽培器シリーズ】
色々と水耕栽培で育てています。
IPA プロマネ落ちました
4月にIPAのプロジェクトマネージャ試験を受けました。
この試験の結果が先週の金曜日発表になりました。上の記事にも書いた通り、あまり良い出来では無かったので、多分無理だろう、と思いつつ、ミラクルを期待して結果を確認。

残念。やっぱり午後2で落ちました...。
午後2の論文は散々な出来だと思っていたので、あれでもB評価を貰えるということは、そこまで厳しい判定ではなさそう。これは次回に希望が持てます。
敗因は論文を自分で書く、という演習を全くやらなかったこと。2時間で論文を書くことに慣れておかなければいけないですね。
この準備をしっかりとして、来年は絶対合格しようと思います。
さて、秋のIPAですが、システムアーキテクトを受験しようと思います。こいつも午後2は論文なので、今度はしっかりと準備したい。逆にここで慣れてしまえば、来年のプロマネはあまり準備が要らないかもしれません。上手いこと軌道に乗せて連続合格を目指したいです。
統計検定2級自己採点
先日、撃沈宣言をした統計検定2級の解答が発表されていたので自己採点を行いました。
結果、
24/35 → 正答率69%
...あれ、意外と出来ている。
真ん中らへんの問題が全然ダメだと思いきや、意外と点が取れてました。試験終了間際まで空欄の状態だったのを、何とか解けないかと足掻いたのが功を奏した気がします。
どうも色々調べてみると、統計検定の合格ライン、公式では70%と言っていますが実際は60%辺りに当落ラインがある、という話もあって、何だか期待が持てそうな気がしてきました。
マークミスがなければ合格できるかも。ただ、解けた問題からマークしていったので、マークズレが少し心配です。。。 何れにせよ、後は祈るのみ。
統計検定2級受けてきたけど
統計検定。
ちょっと前にこんな記事を書いて、滑り出しは好調だったんですが、その後はあまり対策が出来ず仕舞いでした。
で、昨日(6/16)が受験日。僅かな望みを抱いて受験してきました。
...が敢え無く撃沈。
想像以上に難しかった。
中盤、自信を持って解けた問題が殆ど無かった。
ポイントさえ頭に入れておけば、解いていけるかと思いましたが、そうでもなかった。
もっとちゃんと過去問解いておかないとダメですね。
数日後に解答が発表されるので、自己採点してみますが多分難しそう。
次の11月の試験まで日が空いてしまうので、CBTで受けようか。
悩みます。